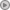Как известно, современный Oscam поддерживает 6 различных форматов ключей в файле SoftCam.Key:
Самый высокий приоритет имеет метод с использованием namespace hash.
Спойлер :
F <namespace hash> 00000000 <key>
Namespace hash - это уникальный идентификатор для отдельной системы, на 100% позволяет избежать конфликта ключей, вычисляется эмулятором автоматически с использованием алгоритма crc32 (способ цифровой идентификации некоторой последовательности данных, который заключается в вычислении контрольного значения ее циклического избыточного кода).
Oscam рассчитывает namespace hash используя язык С. Вот мне и стало интересно, как же это можно реализовать на Python. В общем виде это выглядит так:
Исходными данными у нас является строка 'XXXXXXXXXXXX', сначала мы преобразовываем эти шестнадцатеричные данные в строку ascii, потом отправляем ее в функцию crc32(), которая возвращает рассчитанный namespace hash и напоследок распечатываем результат.
Подготовка исходных данных.
Как известно в Энигме2 существует два пространства имен: полное и урезанное.
Полное пространство имен это орбитальная позиция + частота, например в DEC 30157655 = 1CC2B57 в HEX, где 01CC = 460, то есть спутник 46Е, а 2B57 = 11095 это частота.
Урезанное пространство имен это орбитальная позиция + 0000, например в DEC 49152000 = 2EE0000 в HEX, где 02EE = 750, то есть спутник 75Е, а частота отброшена и заменена нолями.
Почему Энигма2 так делает? Я нашел только такое более менее ясное объяснение: "Если два идентификатора tsid и onid имеют несколько значимые значения (например, не должны быть одновременно 0 или 1). В этом случае Enigma2 считает комбинацию tsid и onid допустимой, а в пространстве имен удаляется (т. е. отсутствует) частотная часть."
У меня из 18 каналов в BISS только три имеют полное пространство имен, а остальные урезанное.
Пример для полного пространства имен.
Канал SETANTA SPORTS 1 46Е 11024 Н sid 000F пространство имен 30157584 = 01CC2B10
Берем 01CC2B10 и в нашем пространстве имен мы очищаем 4 старших бита (в случае DVB-T или DVB-C это 0xF или 0xE соответственно, для DVB-S это 0) и заменяем их на 0xA. Это флаг, чтобы эмулятор мог сказать, что это пространство имен, а не другой pid, например audio и т. д.
Изменяем пространство имен 0х01CC2B10 путем добавления идентификатора 0xA: ==> 0хA1CC2B10.
Затем перед ним размещаем наш sid, получается 000FA1CC2B10 Мы размещаем их так: [srvid][namespace], таким образом мы получаем последовательность длиной 2+4=6 байт.
Это и есть data = '000FA1CC2B10' после вычисления получаем для канала SETANTA SPORTS 1 namespace hash равный 7bb6109f
Пример для урезанного пространства имен.
В случае урезанного пространства имен мы дополнительно используем tsid и onid в нашем хэше, поэтому оно по-прежнему уникально. Размещаем тогда вот так: [srvid][tsid][onid][namespace] и получаем последовательность 2+2+2+4=10 байт.
Канал Shanson TV Int. 80Е 11106 Н sid 02CE tsid 00CD onid 0001 пространство имен 52428800 = 03200000
0x03200000
0xA: ==> A3200000
onid: ==> 0001A3200000
tsid: ==> 00CD0001A3200000
sid: ==> 02CE00CD0001A3200000
Это и есть data = '02CE00CD0001A3200000' после вычисления получаем для канала Shanson TV Int. namespace hash равный 91a8bc48
В общем, написал коротенькую программу Namespace hash Calculator, которая ищет в ресивере каналы в BISS и рассчитывает для каждого Namespace hash. Скопировать файл Namespace_hash_Calculator.py в ресивер, например в /tmp, присвоить права 755, и запустить командой /tmp/Namespace_hash_Calculator.py, результаты появятся в терминале, а также будут записаны в файл /tmp/NamespaceHash.txt для удобства.
Также ее можно запускать и на компьютере, прописав локальный путь к файлу lamedb (строка 20), нужный путь для файла NamespaceHash.txt (строка 21) и возможные пути к файлу satellites.xml.
Единственное ограничение, что для работы нужен только Python версии 2.7...., что в ресивере, что на компьютере.
Так же выше приведенный код можно запускать в интернете, в любой Online Python 2 IDE, предварительно вписав в строку data = 'XXXXXXXXXXXX' нужное значение.
Практическое применение вряд ли сильно востребовано, но для общего развития годится
 Мобильная версия | Карта сайта | Отказ от ответственности | Реклама
Мобильная версия | Карта сайта | Отказ от ответственности | Реклама